Containers allow software to run dependably and consistently when moved from one computing environment to another. This could be from a laptop to a test environment, from a staging environment into production, or from a physical machine to a virtual machine. Here’s a breakdown of the how the popular technology works.
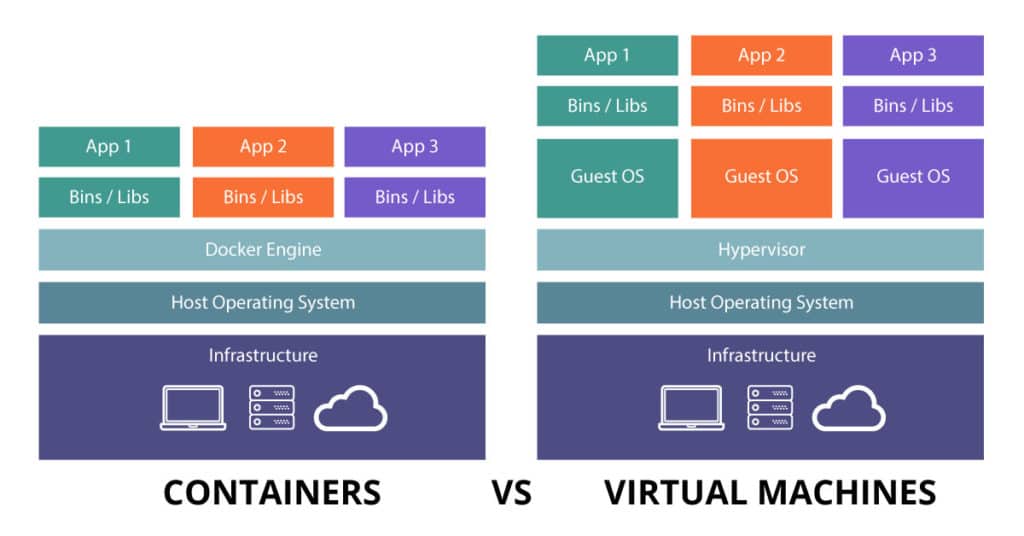
Containers Vs. Virtualization
In the early and mid-2000s, there was a degree of interest in attempting to isolate process and application environments into “containers.” The goals of containerization were significantly different than the other major system for isolating software virtualization. In virtualization, hardware is emulated in software. This provides the benefit that a single virtualization server (called a hypervisor) can run software from many different operating systems (or even processor architectures); but comes with a performance cost. The virtualization layer can have a dramatic effect on the efficiency of the software, sometimes up to 30% when compared to running the same workload on a physical server, because of overhead in passing instructions to the underlying hypervisor for execution.
How A Container Can Solve this Problem
Instead of running isolated processes on a virtual CPU, containers sought to share the kernel (removing the overhead) while still allowing the benefits of the virtual machine. Containers have become the core unit for implementing microservices. Docker created a new technology that solved many of the challenges inherent in packaging software and provided a compelling alternative to virtualization. Specifically, containers allowed for a way to package source code, environment, and configuration. Through the utilization of file layers (and a library of layers called Docker Hub), containers could share common history. This means that if there are two containers, both created a Red Hat layer, both of the child containers could reference the parent and store any differences. This allows for more efficient transport and storage.

Kubernetes
Google has been a leader in the adoption of containers and their utilization at scale for a very long time. Many of their services – search, GMail, and Maps – run in containers and Google has been generous to share their enormous experience with the challenges of administering software at scale. The result is Kubernetes. To solve the problem of running vast numbers of containers on thousands of servers, Google developed a container orchestration engine called Borg. Inside of Google, Borg manages the job of finding and allocating resources and then scheduling containers to run on a group of servers. Over time, the ecosystem grew to include tools for configuring and updating jobs, predicting resource requirements, dynamically pushing configuration files, service discovery and load balancing, auto-scaling, machine lifecycle management, and quota management. While enormously powerful, Borg is also tied to many of Google’s internal technologies and it would not be possible to release as open source code.
The Takeaway
By using a container to package environments, developers can stay focused on shipping software and DevOps engineers can take the resulting containers and map them to an appropriate configuration for deployment in Kubernetes.
Start Your Transformation with DVO Consulting!
Contact us to learn more about containers and how DVO Consulting can help you take advantage of containerization to more rapidly delivery your software and better engage your customers.